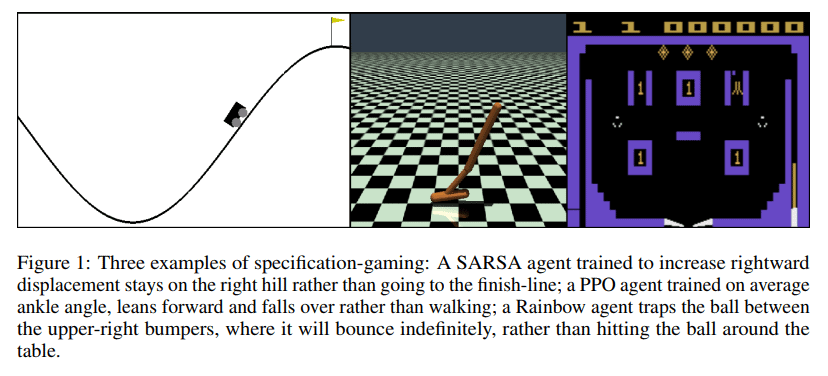
Andrew Critch on AI Research Considerations for Human Existential Safety
- Find the podcast on:




In this episode of the AI Alignment Podcast, Andrew Critch joins us to discuss a recent paper he co-authored with David Krueger titled AI Research Considerations for Human Existential Safety. We explore a wide range of issues, from how the mainstream computer science community views AI existential risk, to the need for more accurate terminology in the field of AI existential safety and the risks of what Andrew calls prepotent AI systems. Crucially, we also discuss what Andrew sees as being the most likely source of existential risk: the possibility of externalities from multiple AIs and AI stakeholders competing in a context where alignment and AI existential safety issues are not naturally covered by industry incentives.
Topics discussed in this episode include:
- The mainstream computer science view of AI existential risk
- Distinguishing AI safety from AI existential safety
- The need for more precise terminology in the field of AI existential safety and alignment
- The concept of prepotent AI systems and the problem of delegation
- Which alignment problems get solved by commercial incentives and which don’t
- The threat of diffusion of responsibility on AI existential safety considerations not covered by commercial incentives
- Prepotent AI risk types that lead to unsurvivability for humanity
Timestamps:
0:00 Intro
2:53 Why Andrew wrote ARCHES and what it’s about
6:46 The perspective of the mainstream CS community on AI existential risk
13:03 ARCHES in relation to AI existential risk literature
16:05 The distinction between safety and existential safety
24:27 Existential risk is most likely to obtain through externalities
29:03 The relationship between existential safety and safety for current systems
33:17 Research areas that may not be solved by natural commercial incentives
51:40 What’s an AI system and an AI technology?
53:42 Prepotent AI
59:41 Misaligned prepotent AI technology
01:05:13 Human frailty
01:07:37 The importance of delegation
01:14:11 Single-single, single-multi, multi-single, and multi-multi
01:15:26 Control, instruction, and comprehension
01:20:40 The multiplicity thesis
01:22:16 Risk types from prepotent AI that lead to human unsurvivability
01:34:06 Flow-through effects
01:41:00 Multi-stakeholder objectives
01:49:08 Final words from Andrew
Citations:
AI Research Considerations for Human Existential Safety
We hope that you will continue to join in the conversations by following us or subscribing to our podcasts on Youtube, Spotify, SoundCloud, iTunes, Google Play, Stitcher, iHeartRadio, or your preferred podcast site/application. You can find all the AI Alignment Podcasts here.

Lucas Perry: Welcome to the AI Alignment Podcast. I’m Lucas Perry. Today we have a conversation with Andrew Critch where we explore a recent paper of his titled AI Research Considerations for Human Existential Safety, which he co-authored with David Krueger. In this episode, we discuss how mainstream computer science views AI existential risk, we develop new terminology for this space and discuss the need for more precise concepts in the field of AI existential safety, we get into which alignment problems and areas of AI existential safety Andrew expects to be naturally solved by industry and which won’t, and we explore the risk types of a new concept Andrew introduces, called prepotent AI, that lead to unsurvivability for humanity.
I learned a lot from Andrew in this episode and found this conversation to be quite perspective shifting. I think Andrew offers an interesting and useful critique of existing discourse and thought, as well as new ideas. I came away from this conversation especially valuing thought around the issue of which alignment and existential safety issues will and will not get solved naturally by industry and commercial incentives. The answer to this helps to identify crucial areas we should be mindful to figure out how to address outside the normal incentive structures of society, and that to me seems crucial for mitigating AI existential risk.
If you don’t already subscribe or follow this podcast, you can follow us on your preferred podcasting platform, like Apple Podcasts or Spotify, by searching for The Future of Life.
Andrew Critch is currently a full-time research scientist in the Electrical Engineering and Computer Sciences department at UC Berkeley, at Stuart Russell’s Center for Human Compatible AI. He earned his PhD in mathematics at UC Berkeley studying applications of algebraic geometry to machine learning models. During that time, he cofounded the Center for Applied Rationality and Summer Program on Applied Rationality and Cognition. Andrew has been offered university faculty positions in mathematics and mathematical biosciences, worked as an algorithmic stock trader at Jane Street Capital‘s New York City office, and as a research fellow at the Machine Intelligence Research Institute. His current research interests include logical uncertainty, open source game theory, and avoiding arms race dynamics between nations and companies in AI development.
And with that, let’s get into our conversation with Andrew Critch.
We’re here today to discuss your paper, AI Research Considerations for Human Existential Safety. You can shorten that to ARCHES. You wrote this with David Krueger and it came out at the end of May. I’m curious and interested to know what your motivation is for writing ARCHES and what it’s all about.
Andrew Critch:
Cool. Thanks, Lucas. It’s great to be here. For me, it’s pretty simple. Is that I care about existential safety. I want humans to be safe as a species. I don’t want human extinction to ever happen. And so I decided to write a big, long document about that with David. And of course, why now and why these particular problems, I can go more into that.
You might wonder if existential risk from AI is possible, how have we done so much AI research with so little technical level thought about how that works and how to prevent it? And to me, it seems like the culture of computer science and actually a lot of STEM has been to always talk about the benefits of science. Except in certain disciplines that are well accustomed to talking about risks like medicine, a lot of science just doesn’t talk about what could go wrong or how it could be misused.
It hasn’t been until very recently that computer science has really started making an effort as a culture to talk about how things could go wrong in general. Forget x-risk, just anything going wrong. And I’m just going to read out loud this quote to sort of set the context culturally for where we are with computer science right now and how far culturally we are from being able to really address existential risk holistically.
This is a quote from Hecht at the ACM Future of Computing Academy. It came out in 2018, just two years ago. “The current status quo in the computing community is to frame our research by extolling its anticipated benefits to society. In other words, rose colored glasses are the normal lenses through which we tend to view our work. However, one glance at the news these days reveals that focusing exclusively on the positive impacts of a new computing technology involves considering only one side of a very important story. We believe that this gap represents a serious and embarrassing intellectual lapse. The scale of this lapse is truly tremendous. It is analogous to the medical community, only writing about the benefits of a given treatment, completely ignoring the side effects, no matter how serious they are.
What’s more, the public has definitely caught on to our community-wide blind spot and is understandably suspicious of it. After several months of discussion, and idea for acting on this imperative began to emerge. We can leverage the gate keeping functionality of the peer review process. At a high level, our recommended change to the peer review process in computing is straightforward. Peer reviewers should require that papers and proposals rigorously consider all reasonable, broader impacts, both positive and negative.” That’s Hecht, 2018.
With this energy, this initiative from the ACM and other similar mentalities around the world, we now have NeurIPS Conference submissions required to submit broader impact statements that include negative impacts as well as positive.
Suddenly in 2020, contrasted with 2015, it’s becoming okay and normal to talk about how your research could be misused and what could go wrong with it. And we’re just barely able to admit things like, “This algorithm could result in racial bias in judiciary hearings,” or something like that. Which is a terrible, terrible … The fact that we’ve taken this long to admit that and talk about it is very bad. And that’s something as present and obvious as racism. Whereas, existential risk has never been … Extinction has never been present or else we wouldn’t be having this conversation. And so those conversations are even harder to have when it’s not normal to talk about bad outcomes at all. Let alone obvious, in your face, bad outcomes.
Lucas Perry: Yeah. On this podcast, we’re basically only talking to people who are in the AI alignment community and who take x-risk very seriously, who are worried about existential risk from advanced AI systems.
And so we lack a lot of this perspective … Or we don’t have many conversations with people who take the cultural, and I guess, academic perspective of the mainstream machine learning and computer science community. Which is far larger and has much more inertia and mass than the AI alignment community.
I’m curious if you can just paint a little bit more of a picture here of what the state of computer science thinking or non-thinking is on AI existential risk? You mentioned that recently people are starting to at least encourage and it be required as part of a process to have negative impact statements or write about the risks of a technology one is developing. But that’s still not talking about global catastrophic risk. It’s still not talking about alignment explicitly. It’s not talking about existential risk. It seems like a step in the right direction, but some ways to go. What kind of perspective can you give us on all this?
Andrew Critch: I think of sort of EA adjacent to AI researchers as kind of a community, to the extent that EA is a community. And it’s not exactly the same set of people as AI researchers who think about existential risk or AI researchers who think about alignment. Which is yet another set of people. What overlaps heavily, but it’s not the same set.
And I have noticed a tendency that I’m trying to combat here by raising this awareness, not only to computer scientists, but to EA adjacent AI folks. Which is that if you feel sort of impatient, that computer science and AI are not acknowledging existential risks from tech, things are underway and there’s ways of making things better and making things worse.
One way to make things worse is to get irate with people, for caring about risks that you think aren’t big enough. Okay. If you think inequitable loan distribution is not as bad as human extinction, many people might agree with you, but if you’re irate about that and saying, “Why are we talking about that when we should be talking about extinction?” You’re slowing down the process of computer science, transitioning into a more negative outcome-aware field by refusing to cooperate with other people who are trying to raise awareness about negative outcomes.
I think there’s a push to be more aware of negative outcomes and all the negative outcome people need to sort of work together politely, but swiftly, raising the bar for our discourse about negative outcomes. And I think existential risks should be part of that, but I don’t think it should be adversarially positioned relative to other negative outcomes. I think we just need to raise the bar for all of these at once.
And all of these issues have the same enemy, which is those rose colored glasses that wrote all of our grant applications for the past 50 years. Every time you’re asking for public funds, you say how this is going to benefit society. And you better not mention how it might actually make society worse or else you won’t get your grant. Right?
Well, times are changing. You’re allowed to mention and signal awareness of how your research could make things worse. And that’s starting to be seen as a good trait rather than a reason not to give you funding. And if we all work together to combat that rose colored glass problem, it’s going to make everything easier to talk about, including existential risk.
Lucas Perry: All right. So if one goes to NeurIPS and talks to any random person about existential risk or AI alignment or catastrophic risk from AI, what is the average reaction or assumed knowledge or people who think it’s complete bullshit versus people who are neutral about it to people who are serious about it?
Andrew Critch: Definitely my impression right now, this is very rough impression. There’s a few different kinds of reactions that are all like sort of double digits percentage. I don’t know which percentage they are, but one is like, how are you worried about existential risks when robots can’t tie knots yet? Or they can’t fold laundry. It’s like a very difficult research problem for an academic AI lab to make a robot fold laundry. So it’s like, come on. We’re so far away from that.
Another reaction is, “Yeah, that’s true. You know, I mean things are really taking off. They’re certainly progressing faster than I expected. Things are kind of crazy.” It’s the things that are kind of crazy reaction and there’s just kind of an open-mindedness. Man, anything could happen. We could go extinct in 50 years, we can go extinct. I don’t know what’s going to happen. Things are crazy.
And then there’s another reaction. Unfortunately, this one’s really weird. I’ve gotten this one, which is, “Well, of course humanity is going to go extinct from the advent of AI technology. I mean, of course. Just think about it from evolutionary perspective. There’s no way we would not go extinct given that we’re making things smarter than us. So of course it’s going to happen. There’s nothing we can do about it. That’s just our job as a field is to make things that are smarter than humans that will eventually replace us and there’ll be better than us. And that’s just how stuff is.”
Lucas Perry: Some people think that’s an aligned outcome.
Andrew Critch: I don’t know. That’s a lot of debate to be had about that. But it’s a kind of defeatist attitude of, “It’s nothing you can do.” It’s much, much rarer. It seems like single digits that someone is like, “Yeah, we’re going to do something about it.” That one is the rarest, the acknowledging and orienting towards solving it is still pretty rare. But there’s plenty these days of acknowledgement that it could be real and acknowledgement that it’s confusing and hard. The challenge is somehow way more acknowledged than any particular approach to it.
Lucas Perry: Okay. I guess that’s surprising to hear then that you feel like it’s more taken seriously than not.
Andrew Critch: It depends on what you mean by taken seriously. And again, I’m filtering for a person who’s being polite and talking to me about it, right? People are polite enough to fall into the, “Stuff is crazy. Who knows what could happen,” attitude.
And is that taking it seriously? Well, no, but it’s not adversarial to people who are taking it seriously, which I think is really good. And then there’s the, “Clearly we’re going to be destroyed by machines that replace us. That’s just nature.” Those voices, I’m kind of like, well, that’s kind of good also. It’s good to admit that there’s a real risk here. It’s kind of bad to give up on it, in my opinion. But altogether, if you add up the, “Woah, stuff’s crazy and we’re not really oriented to it,” plus the, “Definitely humanity is going to be destroyed/replaced.” It’s a solid chunk of people. I don’t know. I’m going to say at least 30%. If you also then include the people who want to try and do something about it. Which is just amazing compared to say six years ago where the answer would have been round to zero percent.
Lucas Perry: Then just to sum up here, this paper then is an exercise in trying to lay out a research agenda for existential safety from AI systems, which is unique in your view? I think you mentioned that there are four that have already existed to this day.
Andrew Critch: Yeah. There’s Aligning Superintelligence with Human Interests, by Soares and Fallenstein, that’s MIRI, basically. Then there’s Research Priorities for A Robust And Beneficial Artificial Intelligence, by Stuart Russell, Max Tegmark, and Daniel Dewey. Then there’s Concrete Problems in AI Safety, by Dario Amodei and others. And then Alignment for Advanced Machine Learning Systems, by Jessica Taylor and others. And Scalable Alignment Via Reward Modeling by Jan Leike and also David Krueger is on that one.
Lucas Perry: How do you see your paper as fitting in with all of the literature that already exists on the problem of AI alignment and AI existential risk?
Andrew Critch: Right. So it’s interesting you say that there exists literature on AI existential risk. I would say Superintelligence, by Nick Bostrom, is literature on AI existential risk, but it is not a research agenda.
Lucas Perry: Yeah.
Andrew Critch: I would say Aligning Superintelligence with Human Interests, by Soares and Fallenstein. It’s a research agenda, but it’s not really about existential risk. It sort of mentions that stakes are really high, but it’s not constantly staying in contact with the concept of extinction throughout.
If you take a random excerpt of any page from it and pretend that it’s about the Netflix challenge or building really good personal assistants or domestic robots, you can succeed. That’s not a critique. That’s just a good property of integrating with research trends. But it’s not about the concept of existential risk. Same thing with Concrete Problems in AI Safety.
In fact, it’s a fun exercise to do. Take that paper. Pretend you think existential risk is ridiculous and read Concrete Problems in AI Safety. It reads perfectly as you don’t need to think about that crazy stuff, let’s talk about tipping over vases or whatever. And that’s a sign that it’s an approach to safety that it’s going to be agreeable to people, whether they care about x-risk or not. Whereas, this document is not going to go down easy for someone who’s not willing to think about existential risk and it’s trying to stay constantly in contact with the concept.
Lucas Perry: All right. And so you avoid making the case for AI x-risk as valid and as a priority, just for the sake of the goal of the document succeeding?
Andrew Critch: Yeah. I want readers to spend time inhabiting the hypothetical that existential risk is real and can come from AI and can be addressed through research. They’re already taking a big step by constantly thinking about existential risk for these 100 pages here. I think it’s possible to take that step without being convinced of how likely the existential risk is. And I’m hoping that I’m not alienating anybody if you think it’s 1%, but it’s worth thinking about. That’s good. If you think it’s 30% chance of existential risk from AI, then it’s worth thinking about. That’s good, too. If you think it’s 0.01, but you’re still thinking about it, you’re still reading it. That’s good, too. And I didn’t want to fracture the audience based on how probable people would agree the risks are.
Lucas Perry: All right. So let’s get into the meat of the paper, then. It would be useful, I think, if you could help clarify the distinction between safety and existential safety.
Andrew Critch: Yeah. So here’s a problem we have. And when I say we, I mean people who care about AI existential safety. Around 2015 and 2016, we had this coming out of AI safety as a concept. Thanks to Amodei and the Robust and Beneficial AI Agenda from Stuart Russell, talking about safety became normal. Which was hard to accomplish before 2018. That was a huge accomplishment.
And so what we had happen is people who cared about extinction risk from artificial intelligence would use AI safety as a euphemism for preventing human extinction risk. Now, I’m not sure that was a mistake, because as I said, prior to 2018, it was hard to talk about negative outcomes at all. But it’s at this time in 2020 a real problem that you have people … When they’re thinking existential safety, they’re saying safety, they’re saying AI safety. And that leads to sentences like, “Well, self driving car navigation is not really AI safety.” I’ve heard that uttered many times by different people.
Lucas Perry: And that’s really confusing.
Andrew Critch: Right. And it’s like, “Well, what is AI safety, exactly, if cars driven by AI, not crashing, doesn’t count as AI safety?” I think that as described, the concept of safety usually means minimizing acute risks. Acute meaning in space and time. Like there’s a thing that happens in a place that causes a bad thing. And you’re trying to stop that. And the Concrete Problems in AI Safety agenda really nailed that concept.
And we need to get past the concept of AI safety in general if what we want to talk about is societal scale risk, including existential risk. Which it’s acute on a geological time scale. Like you can look at a century before and after and see the earth is very different. But a lot of ways you can destroy the earth don’t happen like a car accident. They play out over a course of years. And things to prevent that sort of thing are often called ethics. Ethics are principles for getting a lot of agents to work together and not mess things up for each other.
And I think there’s a lot of work today that falls under the heading of AI ethics that are really necessary to make sure that AI technology aggregated across the earth, across many industries and systems and services, will not result collectively in somehow destroying humanity, our environment, our minds, et cetera.
To me, existential safety is a problem for humanity on an existential timescale that has elements that resemble safety in terms of being acute on a geological timescale. But also resemble ethics in terms of having a lot of agents, a lot of different stakeholders and objectives mulling around and potentially interfering with each other and interacting in complicated ways.
Lucas Perry: Yeah. Just to summarize this, people were walking around saying like, “I work on AI safety.” But really, that means that I’ve bought into AI existential risk and I work on AI existential risk. And then that’s confusing for everyone else, because working on the personal scale risk of self-driving car safety is also AI safety.
We need a new word, because AI safety really means acute risks, which can range from personal all the way to civilizational or transgenerational. And so, it’s confusing to say I work in AI safety, but really what I mean is only I care about transgenerational, AI existential risk.
Andrew Critch: Yes.
Lucas Perry: Then we have this concept of existential safety, which for you both has this portion of us not going extinct, but also existential safety includes the normative and ethics and values and game theory and how it is that an ecosystem of human and nonhuman agents work together to build a thriving civilization that is existentially preferable to other civilizations.
Andrew Critch: I agree 100% with everything you just said, except for the part where you say “existentially preferable.” I prefer to use existential safety to refer really, to preserving existence. And I prefer existential risk to refer to extinction. That’s not how Bostrom uses the term. And he introduced the term, largely, and he intends to include risks that are as important as extinction, but aren’t extinction risks.
And I think that’s interesting. I think that’s a good category of risks to think about and deserving of a name. I think, however, that there’s a lot more debate about what is or isn’t as bad as extinction. Whereas, there’s much less debate about what extinction is. There still is debate. You can say, “Well, what about if we become uploads, whatever.” But there’s much, much more uncertainty about what’s worse or better than extinction.
And so I prefer to focus existential safety on literally preventing extinction and then use some other concept, like societal scale risk, for referring to risks that are really big on a societal scale that may or may not pass the threshold of being worse or better than extinction.
I also care about societal scale risks and I don’t want people working on preventing societal scale risks to be fractured based on whether they think any particular risk, like lots of sentient suffering AI systems or a totalitarian regime that lasts forever. I don’t want people working to prevent those outcomes to be fractured based on whether or not they think those outcomes are worse than extinction or count as a quote, unquote existential risk. When I say existential risk, I always mean risks to the existence of the human species, for simplicity sake.
Lucas Perry: Yeah. Because Bostrom’s definition of an existential risk is any risk such that if it should occur, would permanently and drastically curtail the potential for earth originating, intelligent life. Which would include futures of deep suffering or futures of being locked into some less than ideal system.
Andrew Critch: Yeah. Potential not only measured in existence, but potential measured in value. And if you’re suffering, the value of your existence is lower.
Lucas Perry: Yeah. And that there are some futures where we still exist, where they’re less preferable to extinction.
Andrew Critch: Right.
Lucas Perry: You want to say, okay, there are these potential suffering risks and there are bad futures of disvalue that are maybe worse than extinction. We’re going to call all these societal risks. And then we’re just going to have existential risk or existential safety refer to us not going extinct?
Andrew Critch: I think that’s especially necessary in computer science. Because if anything seems vague or unrefined, there’s a lot of allergy to it. I try to pick the most clearly definable thing, like are humans there or not? That’s a little bit easier for people to wrap their heads around.
Lucas Perry: Yeah. I can imagine how in the hard sciences people would be very allergic to anything that was not sufficiently precise. One final distinction here to make is that one could say, instead of saying, “I work on AI safety,” “I work on AI existential safety or AI civilizational or societal risk.” But another word here is, “I work on AI alignment.” And you distinguish that from AI delegation. Could you unpack that a little bit more and why that’s important to you?
Andrew Critch: Yeah. Thanks for asking about that. I do think that there’s a bit of an issue with the “AI alignment” concept that makes it inadequate for existential risk reduction. AI existential safety is my goal. And I think AI alignment, the way people usually think about it, is not really going to cut it for that purpose.
If we’re successful as a society in developing and rolling out lots of new AI technologies to do lots of cool stuff, it’s going to be a lot of stakeholders in that game. It’s going to be what you might call massively multipolar. And in that economy or society, a lot of things can go wrong through the aggregate behavior of individually aligned systems. Like just take pollution, right? No one person wants everybody else to pollute the atmosphere, but they’re willing to do it themselves. Because when Alice pollutes the atmosphere, Alice gets to work on time or Alice gets to take a flight or whatever.
And she harms everybody in doing that, including herself. But the harm to herself is so small. It’s just a drop in the bucket that’s spread across everybody else. You do yourself a benefit and you do a harm that outweighs that benefit, but it’s spread across everybody and accrues very little harm specifically to you. That’s the problem with externalities.
I think existential risk is most likely to obtain through externalities, between interacting systems that somehow were not designed to interact well enough because they had different designers or they had different stakeholders behind them. And those competitive effects, like if you don’t take a car, everyone else is going to take a car you’re going to fall behind. So you take a car. If you’re a country, right? If you don’t burn fossil fuels, well, you spend a few years transitioning to clean energy and you fall behind economically. You’re taking a hit and that hurts you more than anybody. Of course, it benefits the whole world if you cut your carbon emissions, but it’s just a big prisoner’s dilemma. So you don’t do it. No one does it.
There’s many, many other variables that describe the earth. This comes to the human fragility thesis, which I and David outlined in the paper. Which is that there’s many variables, which if changed, can destroy humanity. And any of those variables could be changed in ways that don’t destroy machines. And so we are at risk of machine economies operating in ways that keep on operating at the expense of humans that aren’t needed for them being destroyed. That is the sort of backdrop for why I think delegation is a more important concept than alignment.
Delegation is a relationship between groups of people. You’ll often have a board of directors that delegates through a CEO to an entire staff. And I want to evoke that concept, the relationship between a group of overseers and a group of doers. You can have delegates on a UN committee from many different countries. You’ve got groups delegating to individuals to serve as part of a group who are going to delegate to a staff. There’s this constant flow through of responsibility. And it’s not even acyclic. You’ve got elected officials who are delegated by the electorate who delegate staff to provide services to the electorate, but also to control the electorate.
So there’s these loops going around. And I think I want to draw attention to all of the delegation relationships that are going to exist in the future economy. And that already exist in the present economy of AI technologies. When you pay attention to all of those different pathways of delegation, you realize there’s a lot of people in institutions with different values that aren’t going to agree with each other on what counts as aligned.
For example, for some people, it’s aligned to take a 1% chance of dying to double your own lifespan. Some people are like, “Yeah, that’s totally worth it.” And for some people, they’re like, “No 1% dying. That’s scary and I’m pretty happy living 80 years.” And so what sort of societal scale risks are worth taking are going to be subject to a lot of disagreement.
And the idea that there’s this thing called human values, that we’re all in agreement about. And there’s this other thing called AI that just has to do with the human value says. And we have to align the AI with human values. It’s an extremely simplified story. It’s got two agents and it’s just like one big agent called the humans. And then there’s this one big agent called AIs. And we’re just trying to align them. I think that is not the actual structure of the delegation relationship that humans and AI systems are going to have with respect to each other in the future. And I think alignment is helpful for addressing some delegation relationships, but probably not the vast majority.
Lucas Perry: I see where you’re coming from. And I think in this conception alignment, as you said, I believe is a sub category of delegation.
Andrew Critch: Well, I would say that alignment is a sub problem of most delegation problems, but there’s not one delegation problem. And I would also say alignment is a tool or technique for solving delegation problems.
Lucas Perry: Okay. Those problems all exist, but actually doing AI alignment, that automatically brings in delegation problems. And, or if you actually align a system, then this system is aligned with how we would want to solve delegation problems.
Andrew Critch: Yeah. That’s right. One approach to solving AI delegation, you might think, “Yeah, we’re going to solve that problem by first inventing a superintelligent machine.” Like step one, invent your super intelligent oracle machine step two align your super intelligent oracle machine with you, the creator. Step three, ask it to solve for society. Just figure out how society should be structured. Do that. That’s a mathematically valid approach. I just don’t think that’s how it’s going to turn out. The closer powerful institutions get to having super powerful AI systems, political tensions are going to arise.
Lucas Perry: So we have to do the delegation problem as we’re going?
Andrew Critch: Yes, we have to do it as we’re going, 100%.
Lucas Perry: Okay.
Andrew Critch: And if we don’t, we put institutions at odds with each other to win the race of being the one chosen entity that aligns the one chosen superintelligence with their values or plan for the future or whatever. And I just think that’s a very non-robust approach to the future.
Lucas Perry: All right. Let’s pivot here then back into existential safety and normal AI safety. What do you see as the relationship between existential safety and safety for present day AI systems? Does safety for present day AI systems feed into existential safety? Can it inform existential safety? How much does one matter for the other?
Andrew Critch: The way I think of it, it’s a bit of a three node diagram. There’s present day AI safety problems, which I believe feed into existential safety problems somewhat. Meaning that some of the present day solutions will generalize to the existential safety problems.
There’s also present day AI ethics problems, which I think also feed into understanding how a bunch of agents can delegate to each other and treat each other well in ways that are not going to add up to destructive outcomes. That also feeds into existential safety.
And just to give concrete examples, let’s take car doesn’t crash, right? What does that have in common with existential safety? Well, existential safety is humanity doesn’t crash. There’s a state space. Some of the states involve humanity exists. Some of the states involve humanity doesn’t exist. And we want to stay in the region of state space where humans exist.
Mathematically, it’s got something in common with the staying in the region of state space where the car is on the road and not overheating, et cetera, et cetera. It’s a dynamical system. And it’s got some quantities that you want to conserve and there’s conditions or boundaries you want to avoid. It has this property just like culturally, it has the property of acknowledging a negative outcome and trying to avoid it. That’s, to me, the main thing that safety and existential safety have in common, avoiding a negative outcome. So is ethics about avoiding negative outcomes. And I think those both are going to flow into existential safety.
Lucas Perry: Are there some more examples you can make for current day AI safety problems and current day AI ethics problems, just make it a bit more concrete? How does something like robustness to distributional shift take us from aligned systems today to systems that have existential safety in the future?
Andrew Critch: So, conceptually, robustness to distributional shift is about, you’ve got some function that you want to be performed or some condition you want to be met, and then the environment changes or the inputs change significantly from when you created the system, and then you still want it to maintain those conditions or achieve the goal.
So, for example, if you have a car trained, “To drive in dry conditions,” and then it starts raining, can you already have designed your car by principles that would allow it to not catastrophically fail in the rain? Can it notice, “Oh gosh, this is real different from the way I was trained. I’m going to pull over, because I don’t know how to drive in the rain.” Or can it learn, on the fly, how to drive in the rain and then get on with it?
So those are kinds of robustness to distributional shift. The world changes. So, if you want something that’s safe and stays safe forever, it has to account for the world changing. So, principles of robustness to distributional shift are principles by which society, as a whole, needs to adhere. Now, do I think research in this area is differentially useful to existential risk?
No. Frankly, not at all. And the reason is that industry has loads of incentives to produce software that are robust to a changing environment. So, if on the margin I could add an idea to the idea space of robustness to distributional shift, I’m like, “Well, I don’t think there’s any chance that Uber is going to ignore robustness to distributional shift, or that Google is going to ignore, or Amazon.” There’s no way these companies are going to roll out products while not thinking about whether they’re robust.
On the other hand, if I have a person who wants to dwell on the concept of robustness, who cares about existential risk and who wants to think about how robustness even works, like what are the mathematical principles of robustness? We don’t fully know what they are. If we did, we’d have built self driving cars already.
So, if I have a person who wants to think about that concept because it applies to society, and they want a job while they think about it, sure, get a job producing robust software or robust robotics, or get a bunch of publications in that area, but it’s not going to be neglected. It’s more of a mental exercise that can help you orient and think about society through a new lens, once you understand that lens, rather than a thing that somehow DeepMind is going to forget that it’s products need to be robust, come on.
Lucas Perry: So, that’s an interesting point. So, what are technical research areas, or areas in terms of AI ethics that you think there will not be natural incentives for solving, but that are high impact and important for AI existential safety?
Andrew Critch: To be clear, before I go into saying these areas are important, these areas aren’t, I do want to distinguish the claim area X is a productive place to be if you care about existential risk from, area X is an area that needs more ideas to solve existential safety. I don’t want the people to feel discouraged from going into intellectual disciplines that are really nourishing to the way that you’re going to learn and invent new concepts that help you think forever. And it can be a lot easier to do that in an area that’s not neglected.
So, robustness is not going to be neglected. Alignment, taking an AI system and making it do what a person wants, that’s not going to be neglected, because it’s so profitable. The economy is set up to sell to individual customers, to individual companies. Most of the world economy is anarchic in that way, anarcho-capitalist at a global scale. If you can find someone that you can give something to that they like, then you will.
The Netflix challenge is an AI alignment problem, right? The concept of AI alignment was invented in 2002, and nobody cites it because it’s so obvious of an idea that you have to make your AI do stuff. Still, it was neglected in academia because AI wasn’t super profitable. So, it is true that AI alignment was not a hot area of research in academia, but now, of course, you need AI to learn human preferences. Of course, you need AI to win in the tech sphere. And that second part is new.
So, because AI is taking off industrially, you’ve got a lot more demand for research solutions to, “Okay. How do we actually make this useful to people? How do we get this to do what people want?” And that’s why AI alignment is taking off. It’s not because of existential risk, it’s because well, AI is finally super-duper useful and it’s finally super-duper profitable, if you can just get it to do what the customer wants. So, that’s alignment. That’s what user agent value alignment is called.
Now, is that a productive place to be if you care about existential risks? I think. Yes. Because if you’re confused about what values are and how you could possibly get an inhuman system to align with the values of a human system, like human society, if that basic concept is tantalizing to you and you feel like if you just understood it a bit more, you’d be better mentally equipped to visualize existential risk playing out or not playing it on a societal scale, then yeah, totally go into that problem, think about it. And you can get a job as a researcher or an engineer aligning AI systems with the values of the human beings who use it. And it’s super enriching and hard, but it’s not going to be neglected because of how profitable it is.
Lucas Perry: So what is neglected, or what is going to be neglected?
Andrew Critch: What’s going to be neglected is stuff that’s both hard and not profitable. Transparency, I think, is not yet profitable, but it will be. So it’s neglected now. And when I say it’s not yet profitable, I mean that as far as I know, we don’t have big tech companies crushing their competition by having better visualization techniques for their ML systems. You don’t see advertisements for, “Hey, we’re hiring transparency engineers,” yet.
And so, I take that as a sign that we’ve not yet reached the industrial regime in which the ability for engineers to understand their systems better is the real bottleneck to rolling out the next product. But, I think it will be if we don’t destroy ourselves first. I think there’s a very good chance of that actually playing out.
So I think, if you want an exciting career, get into transparency now. In 10 years, you’ll be in high demand and you’ll have understood a problem that’s going to help humans and machines relate, which is, “Can we understand them well enough to manage them?” There’s other problems, unfortunately, that I think are neglected now and important, and are going to stay neglected. And I think those are the ones that are most likely to kill us.
Lucas Perry: All right, let’s hear them.
Andrew Critch: Things like how do we get multiple AI systems from multiple stakeholders to cooperate with each other? How do you broker a peace treaty between Uber and Waymo cars? That one’s not as hard because you can have the country that allows the cars into it have some regulatory decision that all the cars have to abide by, and now the cars have to get along or whatever.
Or maybe you can get the partnership on AI, which is largely American to agree amongst themselves that there’s some principles, and then the cars adhere to those principles. But it’s much harder on an international scale where there’s no one centralized regulatory body that’s just going to make all the AIs behave this way or that way. And moreover, the people who are currently thinking about that, aren’t particularly oriented towards existential risk, which really sucks.
So, I think what we need, if we get through the next 200 years with AI, frankly, if we get through the next 60 years with AI, it’s going to be because people who cared about existential risk entered institutions with the power to govern the global deployment of AI, or people already with the power to govern the global deployment of AI technologies come to care about existential and comparable societal scale risks. Because without that, I think we’re going to miss the mark.
When something goes wrong and there’s somebody whose job was clearly to make that not happen, it’s a lot easier to get that fixed. Think about people who’ve tried to get medical care since the COVID pandemic. Everybody’s decentralized, the offices are part work from home, partly they’re actually physically in there. So you’re like, “Hey, I need an appointment with a neurologist.” The person whose job it is to make the appointment is not the person whose job it is to tell the doctor that the appointment is booked.
It’s also, there’s someone else’s job is to contact the insurance company and make sure that you’re authorized. And they might be off that day, and then you show up, and you get a big bill and you’re like, “Well, whose fault was this?” Well, it’s your fault because you’re supposed to check that your insurance covered this neurology stuff, right? You could have called your insurance company to pre-authorize this visit.
So it’s your fault. But also, it’s the administrator’s fault that you didn’t talk to that never meets you, whose job is to conduct the pre-authorization on the part of the doctor’s office, which sometimes does it, right? And it’s also the doctor’s fault, because maybe the doctor could have noticed that the authorization hadn’t been done, and didn’t cancel the appointment or warn you that maybe you don’t want to afford this right now. So whose fault is it? Oh, I don’t know.
And if you’ve ever dealt with a big fat bureaucratic failure like this, that is what is going to kill humanity. Everybody knows it’s bad. Nobody in this system, not the insurance company, not the call center that made my appointment, not the insurance specialist at the doctor’s office, certainly not the doctor, none of these people want me not to get healthcare, but it’s no one in particular’s fault. And that’s how it happens.
I think the same thing is going to happen with existential risk. We’re going to have big companies making real powerful AI systems, and it’s going to be really obvious that it is their job to make those systems safe. And there’s going to be a bunch of kinds of safety that’s really obviously their job that people are going to be real angry at them for not paying a lot of attention to. And the anger is just going to get more and more, the more obvious it is that they have power.
That kind of safety, I don’t want to trivialize it. It’s going to be hard. It’s going to be really difficult research and engineering, and it can be really enriching and many, many thousands of people could make their whole careers around making AI safe for big tech companies, according to their accountable definition of safety.
But then what about the stuff they’re not accountable for? What about geopolitics that’s nobody’s fault? What about coordination failures between three different industries, or three different companies that’s nobody’s fault? That’s the stuff that’s going to get you. I think it’s actually mathematically difficult to specify protocols for decentralized multi-agent systems to adhere to constraints. It is more difficult than specifying constraints for a single system.
Lucas Perry: I’m having a little bit of confusion here, because when you’re arguing that alignment questions will be solved via the incentives of just the commercialization of AI.
Andrew Critch: Single-human, single-AI alignment problems or single-institutions, single-network alignment problems. Yes.
Lucas Perry: Okay. But they also might be making single agents for many people, or multiple agents for many people. So it doesn’t seem single-single to me. But the other part is that you’re saying that in a world where there are many competing actors and a diffusion of responsibility, the existential risk comes from obvious things that companies should be doing, but no one is, because maybe someone should make a regulation about this thing but whatever, so we should just keep doing things the way that we are. But doesn’t that come back to commercialization of AI systems not solving all of the AI alignment problems?
Andrew Critch: So if by AI alignment you mean AI technology in aggregate behaves in a way that is favorable to humanity in aggregate. If that’s what you mean, then I agree that failure to align the entire economy of AI technology is a failure of AI alignment. However, number one, people don’t usually think about it that way.
If you asked someone to write down the AI alignment problem, they’ll write down a human utility function and an AI utility function, and talk about aligning the AI utility function with the human utility function. And that’s not what that looks like. That’s not a clear depiction of that super multi-agent scenario.
And, second of all, the concept of AI alignment has been around for decades and it refers to single-single alignment, typically. And third, if you want to co-op the concept of AI alignment and start using it to refer to general alignment of general AI technology with general human values, just as spread out notion of goodness that’s going to get spread over all of the AI technology and make it all generally good for all the generally humans. If you want to co-opt it and use it for that, you’re going to have a hard time. You’re going to invite a lot of debate about what is human values?
We’re trying to align the AI technology with the human values. So, you go from single-single to single-multi. Okay. Now we have multiple AI systems serving a single human, that’s tricky. We got to get the AI systems to cooperate. Okay. Cool. We’ll figure out how the cooperation works and we’ll get the AI systems to do that. Cool. Now we’ve got a fleet of machines that are all serving effectively.
Okay. Now let’s go to multi-human, multi-AI. You’ve got lots of people, lots of AI systems in this hyper interactive relationship. Did we align the AIs with the humans? Well, I don’t know. Are some of the humans getting really poor, really fast, while some of them are getting really rich, really fast? Sound familiar? Okay. Is that aligned? Well, I don’t know. It’s aligned for some of them. Okay. Now we have a big debate. I think that’s a very important debate and I don’t want to skirt it.
However, I think you can ask the question, did the AI technology lead to human extinction without having that debate? And I want to factor that debate of, wait, who do you mean? Who are you aligning with? I want that debate to be had, and I want it to be had separately from the debate of, did it cause human extinction?
Because I think almost all humans want humanity not to go extinct. Some are fine with it, it’s not universal, but a lot of people don’t want humanity to go extinct. I think the alignment concept, if you play forward 10 years, 20 years, it’s going to invite a lot of very healthy, very important debate that’s not necessary to have for existential safety.
Lucas Perry: Okay. So I’m not trying to defend the concept of AI alignment in relation to the concept of AI existential safety. I think what I was trying to point towards is that you said earlier that you do not want to discourage people from going into areas that are not neglected. And the areas that are not neglected are the areas where the commercialization of AI will drive incentives towards solving alignment problems.
Andrew Critch: That’s right.
Lucas Perry: But the alignment problems that are not going to get solved-
Andrew Critch: I want to encourage people to go out to solve those problems. 100%.
Lucas Perry: Yeah. But just to finish the narrative, the alignment problems that are not going to get solved are the ones where there are multiple humans and multiple AI agents, and there’s this diffusion of responsibility you were talking about. And this is the area you said would most likely lead to AI existential risk. Where maybe someone should make a regulation about this specific thing, or maybe we’re competing a little bit too hard, and then something really bad happens. So you’re saying that you do want to push people into both the unneglected area of…
Andrew Critch: Let me just flesh out a little bit more about my value system here. Pushing people is not nice. If there’s a person and they don’t want to do a thing, I don’t want to push them. That’s the first thing. Second thing is, pulling people is not nice either. So it’s like, if someone’s on the way into doing something they’re going to find intellectually enriching that’s going to help them think about existential safety that’s not neglected, it’s popular, it’s going to be popular, I don’t want to hold them back. But, if someone just comes to me and is like, “Hey, I’m indifferent between transparency and robustness.” I’m like, “100%, go into transparency, no question.”
Lucas Perry: Because it will be more neglected.
Andrew Critch: And if someone tells me they’re indifferent between transparency and multi-stakeholder delegation, I’m like, “100%, multi-stakeholder delegation.” If you’ve got traction on that and you’re not going to burn your career, do it.
Lucas Perry: Yeah. That’s the three categories then though. Robustness gets solved by the incentive structures of commercialization. Transparency, maybe less so, maybe it comes later. And then the multi-multi delegation is just the other big neglected problem of living in a global world. So, you’re saying that much of the alignment problem gets solved by incentive structures of commercialization.
Andrew Critch: Well, a lot of what people call alignment will get solved by present day commercial incentives.
Lucas Perry: Yes.
Andrew Critch: Another chunk of societal scale benefit from AI, I’ll say, will hopefully get solved by the next wave of commercial incentives. I’m thinking things like transparency, fairness, accountability, things like that are actually going to become actually commercially profitable to get right, rather than merely the things companies are afraid of getting wrong.
And I hope that second wave happens before we destroy ourselves, because possibly, we would destroy ourselves even before then. But most of my chips are on, there’s going to be a wave of benefit with AI ethics in the next 10 years or something, and that that’s going to solve a bunch more of existential safety, or it’s going to address them. Leftover after that is stuff that the global capitalism never got to.
Lucas Perry: And the things that global capitalism never got to are the capitalistic organizations and governments competing with one another with very strong AI systems?
Andrew Critch: Yeah. Competing and cooperating.
Lucas Perry: Competing and cooperating, unless you bring in some strong notion of paretotopia where everyone is like, “We know that if we keep doing this, that everyone is going to lose everything they care about.”
Andrew Critch: Well, the question is, how do you bring that in? If you solve that problem, you’ve solved it.
Lucas Perry: Okay. So, to wrap up on this then, as companies increasingly are making systems that serve people and need to be able to learn and adopt their values, the incentives of commercialization will continue to solve what are classically AI alignment problems that may also provide some degree of AI existential safety. And there’s the question of how much of those get solved naturally, and how much we’re going to have to do in academia and nonprofit, and then push that into industry.
So we don’t know what that will be, but we should be mindful about what will be solved naturally, and then what are the problems that won’t be, and then how do we encourage or invite more people to go into areas that are less likely to be solved by natural industrial incentives.
Andrew Critch: And do you mean areas of alignment, or areas of existential safety? I’m serious.
Lucas Perry: I know because I’m guilty of not really using this distinction in the past. Both.
Andrew Critch: Got it. I actually think most of single-single alignment. Like there’s a single stakeholder, which might be a human or an institution that has one goal, like profits, right? So there’s a single-human stakeholder, and then there’s a single-AI. I call that single-single alignment. I almost never refer to a multi-multi alignment, because I don’t know what it means and it’s not clear what the values of multiple different stakeholders even is. What are you referring to when you say the values are this function?
So, I don’t say multi-multi alignment a lot, but I do sometimes say single-single alignment to emphasize that I’m talking about the single stakeholder version. I think the multi-multi alignment concept almost doesn’t make sense. So, when someone asks me a question about alignment, I always have to ask, “Now, are you eliding those concepts again?” Or whatever.
So, we could just say single-single alignment every time and I’ll know what you’re talking about, or we could say classical alignment and I’ll probably assume that you mean single-single alignment, because that’s the oldest version of the concept from 2002. So there’s this concept of basic human rights or basic human needs. And that’s a really interesting concept, because it’s a thing that a lot of people agree on. A lot of people think murder is bad.
Lucas Perry: People need food and shelter.
Andrew Critch: Right. So there’s a bunch of that stuff. And we could say that AI alignment is about that stuff and not the other stuff.
Lucas Perry: Is it not about all of it?
Andrew Critch: I’ve seen satisfactory mathematical definitions of intent alignment. Paul Christiano talks about alignment, which I think of as in intent alignment, I think he now also calls it intent alignment, which is the problem of making sure an AI system is intending to help its user. And I think he’s got a pretty clear conception of what that means. I think the concept of the intent alignment of a single-single AI servant is easier to define than whatever property an AI system needs to have.
There’s a bunch of properties that people call AI alignment that are actually all so different from each other. And people don’t recognize that they’re different from each other, because they don’t get into the technical details of trying to define it, so then everyone thinks that we all mean the same thing. But what really is going on, is everyone’s going around thinking, “I want AI to be good, basically good for basically everybody.” No one’s cashing that out, and so nobody notices how much we disagree on what basically good for basically everybody means.
Lucas Perry: So that’s an excellent point, and I’m guilty here now then of having absolutely no idea of what I mean by AI alignment.
Andrew Critch: That’s my goal, because I also don’t know and I’m glad to have a company in that mental state.
Lucas Perry: Yeah. So, let’s try moving long ahead here. And I’ll accept any responsibility and my guilt in using the word AI alignment incorrectly from now on. That was a fun and interesting side road, and I’m glad we pursued it. But now pivoting back into some important definitions here that you also write about in your paper, what counts to you as an AI system and what counts to you as an AI technology, and why does that distinction matter?
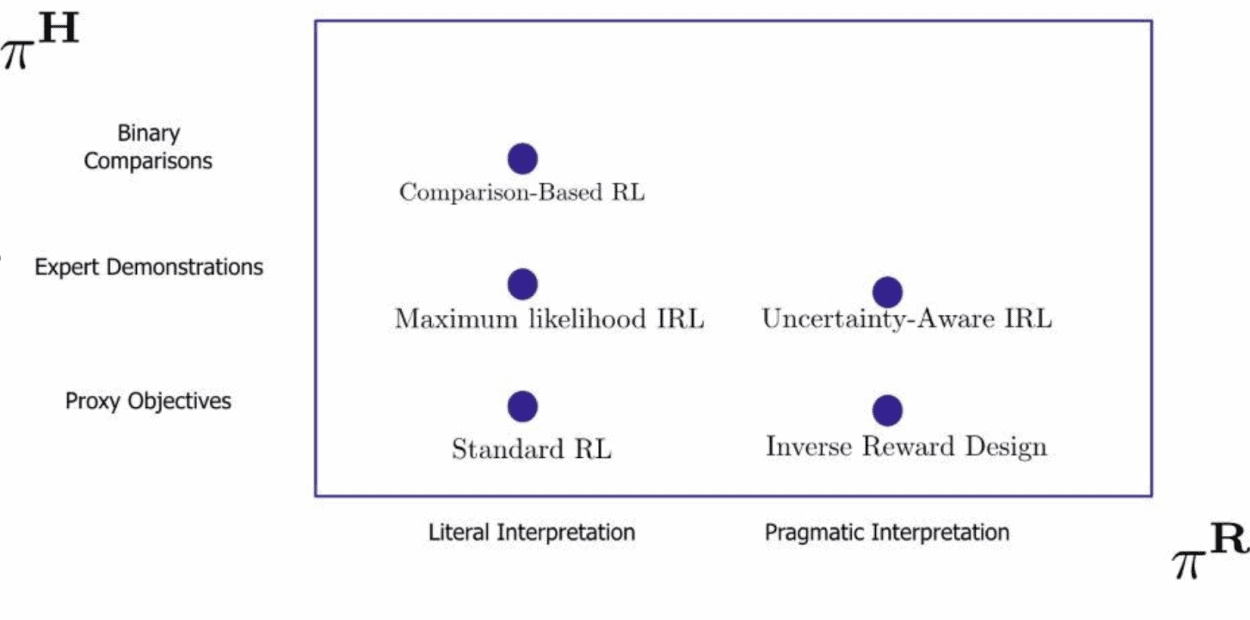
Andrew Critch: So throughout the ARCHES report, I’d advocated for using technology versus system. AI technology is like a mass net, and you can say, you can have more of it or less of it. And it’s like this butter that you can spread on the toast of civilization. And AI system, it’s like a countdown. You can have one of them or many of them, and you can put an AI system like you could put a strawberry on your toast, which is different from strawberry jam.
So, there’s properties of AI technology that could threaten civilization and there’s also properties of a single AI system that could threaten civilization. And I think those are both important frames to think in, because you could make a system and think, “This system is not a threat to civilization,” but very quickly, when you make a system, people can copy it. People can replicate it, modify it, et cetera. And then you’ve got a technology that’s spread out like the strawberry has become strawberry compote and spread out over the toast now. And do you want that? Is that good?
As an everyday person, I feel like basic human rights are a well-defined concept to me. Is this basically good for humanity? Is a well defined concept to me, but mathematically it becomes a lot harder to pin down. So I try to say AI technology when I want to remind people that this is going to be replicated, it’s going to show up everywhere. It’s going to be used in different ways by different actors.
At the same time, you can think of the aggregate use of AI technology worldwide as a system. You can say the internet is a system, or you can say all of the self driving cars in the world is one big system built by multiple stakeholders. So I think that the system concept can be reframed to refer to the aggregate of all the technology of a certain type or of a certain kind. But that mental reframe is an actual act of effort, and you can switch between those frames to get different views of what’s going on. I try to alternate and use both of those views from time to time, the system view and the technology view.
Lucas Perry: All right. So let’s get into another concept here that you develop, and it’s really at the core of your paper. What is a prepotent AI? And I guess before you define what a prepotent AI is, can you define what prepotent means? I had actually never heard of that word before reading your paper.
Andrew Critch: So I’m going to say the actual standard definition of prepotent which connotes, arrogance, overbearing high-handed, despotic, possessing excessive abuse of authority. These connotations are carried across a bunch of different Latin languages, but in English they’re not as strong. In English, prepotent just means very powerful, or superior enforced influence, or authority or predominant.
I used it because it’s not that common of a word, but it’s still a word, and it’s a property that AI technology can have relative to us. And it’s also property that a particular AI system, whether it’s singular or distributed can have relative to us. The definition that I’d give for a prepotent AI technology is technology whose deployment would transform humanity’s habitat, which is currently the earth, in a way that’s unstoppable to us.
So there’s this notion of there’s the transformativeness and then there’s the unstoppableness. Transformativeness is a concept that has been also elaborated by the Open Philanthropy Project. They have this transformative AI concept. I think it’s a very good concept, because it’s impact oriented. It’s not about what the AI’s trying to do, it’s about what impact that has. And they say when AI system or technology is transformative, if its impact on the world is comparable to, say the agricultural revolution or the industrial revolution, a major global change in how things are done. You might argue that the internet is a transformative technology as well.
So, that’s the transformative aspect of prepotence. And then there’s the unstoppable aspect. So, imagine something that’s transforming the world the way the agricultural industrial revolution has transformed it, but also, we can’t stop it. And by we, I mean, no subset of humans, if they decided that they want to stop it, could stop it. If every human in the world decided, “Yeah, we all want this to stop,” we would fail.
I think it’s possible to imagine AI technologies that are unstoppable to all subsets of humanity. I mean, there’s things that are hard to stop right now. If you wanted to stop the use of electricity. Let’s say all humans decided, today, for some strange reason that we never want to use electricity anymore. That’d be a difficult transition. I think we probably could do it, but it’d be very difficult. Humanity as a society can become dependent on certain things, or intertwined with things in a way that makes it very hard to stop them. And that’s a major mechanism by which an AI technology can be prepotent, by being intertwined with us and how we use it.
Lucas Perry: So, can you distinguish this idea of prepotent AI, because it’s a completely new concept from transformative AI, as you mentioned before, and superintelligence, and why it’s important to you that you introduced this new concept?
Andrew Critch: Yeah. Sure. So let’s say you have an AI system that’s like a door-to-door salesman for solar panels, and it’s just going to cover everyone’s roofs with solar panels for super cheap, and all of the business is going to have solar panels on top, and we’re basically just not going to need fossil fuels anymore. And we’re going to be way more decentralized and independent, and states are going to be less dependent on each other for energy. So, that’s going to change geopolitics. A lot of stuff’s going to change, right?
So, you might say that that was transformative. So, you can have a technology that’s really transformative, but also maybe you can stop it. If everybody agreed to just not answer the door when the door-to-door solar panel robot salesman comes by, then they would stop. So, that’s transformative, but not prepotent. There’s a lot of different ways that you can envision AI being both transformative and unstoppable, in other words, prepotent.
I have three examples that I’d go to and we’ve written about those in ARCHES. One is technological autonomy. So if you have a little factory that can make more little factories, and it can do its own science and invent its own new materials to make more robots to do more mining, to make more factories, et cetera, you can imagine a process like that that gets out hand someday. Of course, we’re very far away from that today, conceptually, but it might not be very long before we can make robots that make robots that make robots.
Self-sustaining manufacturing like that could build defenses using technology the way humans build defenses against each other. And now suddenly, the humans want to stop it, but it has nukes aimed at us, so we can’t. Another completely different one which is related, is replication speed. Like the way a virus can just replicate throughout your body and destroy you without being very smart.
You could envision, you can imagine. I don’t know of how easy it is to build this, because maybe it’s a question of nanotechnology, but can you build systems that just very quickly replicate, and just tile the earth so fast with their replicants that we die? Maybe we suffocate from breathing them, or breathing their exhaust. That one honestly seems less plausible to me than to technological autonomy one, but to some people it seems more plausible and I don’t have a strong position on that.
And then there’s social acumen. You can imagine say a centralized AI system that is very socially competent, and it can deliver convincing speeches to the point of becoming elected a state official, and then brokering deals between nations that make it very hard for anybody to go against their plans, because they’re so embedded and well negotiated with everybody. And when you try to coordinate, they just whisper things, or say threats or make offers that dis-coordinate everybody again. Even though everybody wants it to stop, nobody can manage to coordinate long enough to stop it because it’s so socially skilled. So those are like a few science fiction scenarios that I would say constitute prepotence on the part of the AI technology or system. They’re all different and the interesting thing about them is that they all can happen without being generally superintelligent. These are conditions that are sufficient to pose a significant existential threat to humanity, but which aren’t superintelligence. And I want to focus on those because I don’t want us to delay addressing existential risk until we have superintelligence. I want us to address it but the minimum viable existential threats that we could face and head those off. So that’s why I focus on prepotence as a property rather than superintelligence because it’s a broader category that I think is still quite threatening and quite plausible.
Lucas Perry: Another interesting and important concept is born of this is misaligned prepotent AI technology. Can you expand a bit on that? So what is and should count as misaligned prepotent AI technology?
Andrew Critch: So this was a tough decision for me because as you’ve noticed throughout this podcast, at the technical level, I find the alignment concept confusing at multi-stakeholder scales, but still critical to think about. And so I couldn’t decide whether to just talk about unsurvivable prepotent AI or misaligned prepotent AI. So let me talk about unsurvivable prepotent AI. By that, I mean it’s transformed the earth, you can’t stop it and moreover, you’re going to die of it eventually. The AI technology has become unsurvivable in the year 2085 if in that year, the humans now are doomed and cannot possibly survive. And I thought about naming the central concept, unsurvivable prepotent AI but a lot of people want to say for them, misalignment is basically unsurvivability.
I think David also tends to think of alignment in a similar way, but there’s this question of where do you draw the line between poorly aligned and misaligned? We just made a decision to say, extinction is the line, but that’s kind of a value judgment. And one of the things I don’t like about the paper is that it has that implicit value judgment. And I think the way I would prefer people to think is in terms of the concept of unsurvivability versus survivability, or prepotence versus not. But the theme of alignment and misalignment is so pervasive that some of our demo readers preferred that name for the unsurvivable prepotent AIs.
Lucas Perry: So misaligned prepotent AI then is just some AI technology that would lead to human extinction?
Andrew Critch: As defined in the report, yep. That’s where we draw the line between aligned and misaligned. If it’s prepotent, it’s having this huge impact. When’s the huge impact definitively misaligned? Well, it’s kind of like where’s the zero line and we just kind of picked extinction to be the line to call misaligned. I think it’s a pretty reasonable line. It’s pretty concrete. And I think a lot of efforts to prevent extinction would also generalize to preventing other big risks. So sometimes, it’s nice to pick a concrete thing and just focus on it.
Lucas Perry: Yeah. I understand why and I think I would probably endorse doing it this way, but it also seems a little bit strange to me that there are futures worse than extinction and they’re going to be below the line. And I guess that’s fine then.
Andrew Critch: That’s why I think unsurvivable is a better word. But our demo readers, some of them just really preferred misaligned prepotent AI over unsurvivable prepotent AI. So we went with that just to make sense to your readers.
Lucas Perry: Okay. So as we’re building AI technologies, we can ask what counts as the deployment of a prepotent AI system or technology, a TAI system, or a misaligned prepotent AI system and the implications of such deployment? I’m curious to get your view on what counts as the deployment of a prepotent AI system or a misaligned prepotent AI system.
Andrew Critch: So you could imagine something that’s transforming the earth and we can’t stop it, but it’s also great.
Lucas Perry: Yeah. An aligned prepotent AI system.
Andrew Critch: Yeah. Maybe it’s just building a lot of infrastructure around the world to take care of people’s health and education. Some people would find that scary and not like the fact that we can’t stop it, and maybe that fear alone would make it harmful or maybe it would violate some principle of theirs that would matter even if they didn’t feel the fear. But you can at least imagine under some value systems, technology that’s kind of taken over the world but it’s taken good care everybody. And maybe it’s going to take care of everybody forever so humanity will never go extinct. That’s prepotent but not unsurvivable, but that’s a dangerous move to make on a planet to sort of make a prepotent thing and try to make sure that it’s an aligned prepotent thing instead of a misaligned prepotent thing, because you’re unstoppably transforming the earth and you maybe you should think a lot before you do that.
Lucas Perry: And maybe prepotence is actually incompatible with alignment if we think about it enough for the reasons that you mentioned.
Andrew Critch: It’s possible. Yeah. With enough reflection on the value of human autonomy, we would eventually conclude that if humans can’t stop it, it’s fundamentally wrong in a way that will alienate and destroy humans eventually in some way. That said, I do want to add something which is that I think almost all prepotent AI that we could conceivably make will be unsurvivably misaligned. If you’re transforming the world, most states of the world are not survivable to humans. Just like most planets are not survivable to humans. So most ways that the world could be very different are just ways in which humans could not survive. So I think if you have a prepotent AI system, you have to sort of steer it through this narrow window of futures, this narrow like keyhole even of futures where all the variables of the earth stay inhabitable to humans, or we would build some space colony where humans live instead of Earth.
Almost every chemical element, if you just turn up that chemical element on the earth, humans die. So that’s the thing that makes me think most conceivable prepotent AI systems are misaligned or unsurvivable. There are people who think about alignment a lot that I think are super biased by the single principal, single agent framing and have sort of lost track of the complexities of society and that’s why they think prepotent AI is conceivable to align or like not that hard to align or something. And I think they’re confused, but maybe I’m the confused one and maybe it’s actually easy.
Lucas Perry: Okay. So you’ve mentioned a little bit here about if you dial in the knobs of the chemical composition of really anything much on the planet in any direction, that pretty quickly you can create pretty hostile or even existentially incompatible situations on Earth for human beings. So this brings us to the concept of basically how frail humanity is given the conditions that are required for us to exist. What is the importance of understanding human frailty in relation to prepotent AI systems?
Andrew Critch: I think it’s pretty simple. I think human frailty implies don’t make prepotent AI. If we lose control of the knobs, we’re at risk of the knobs getting set wrong. Now that’s not to say we can set the knobs perfectly either, but if they start to go wrong, we can gradually set them right again. There’s still hope that we’ll stop climate change, right? And not saying we will, but it’s at least still possible. We haven’t made it impossible to stop. If every human in the world agreed now to just stop, we would succeed. So we should not lose control of this system because almost any direction it could head is a disaster. So that’s why some people talk about the AI control problem, which is different I claim than the AI alignment problem. Even for a single powerful system, you can imagine it looking after you, but not letting you control it.
And if you aim for that and miss, I think it’s a lot more fraught. And I guess the point is that I want to draw attention to human fragility because I know people who think, “No, no, no. The best thing to do for humanity is to build a super powerful machine that just controls the Earth and protects the humans.” I know lots of people who think that. It makes sense logically. It’s like, “Hey, the humans. We might destroy ourselves. Look at this destructive stuff we’re doing. Let’s build something better than us to take care of us.” So I think the reasoning makes sense, but I think it’s a very dangerous thing to aim for because if we aim and miss, we definitely, definitely die.
I think transformative AI is big enough risk. We should never make prepotent AI. We should not make unstoppable, transformative AI. And that’s why there’s so much talk about the off switch game or the control problem or whatever. Corrigibility is kind of related to turning things off. Humans have this nice property where if half of them are destroyed and the other half of them have the ability to notice that and do something about it, they’re quite likely to do something about it. So you get this robustness at a societal scale by just having lots of off switches.
Lucas Perry: So we’ve talked about this concept a bunch already, this concept of delegation. I’m curious if you can explain the importance and relevance of considering delegation of tasks from a human or humans to an AI system or systems. So we’re just going to unpack this taxonomy that you’ve created a bit here of single-single, single-multi, multi-single, and multi-multi.
Andrew Critch: The reason I think delegation is important is because I think a lot of human society is rightly arranged in a way that avoids absolute power from accumulating into decisions of any one person, even in the most totalitarian regimes. The concept of delegation is a way that humans hand power and responsibility to each other in political systems but also in work situations, like the boss doesn’t have to do all the work. They delegate out and they delegate a certain amount of power to people to allow the employees of a company to do the work. That process of responsibilities and tasks being handed from agent to agent to agent is how a lot of things get done in the world. And there’s many things we’ve already delegated to computers.
I think delegation of specific tasks and responsibilities is going to remain important in the future even as we approach human level AI and supersede human level AI, because people resist the accumulation of power. If you say, “Hey, I am Alpha Corp. I’m going to make a superintelligent machine now and then use it to make the world good.” You might be able to get a few employees that are like kind of wacky enough to think that yeah, taking over the world with your machine is the right company mission or whatever. But the winners of the race of AI development are going to be big teams that won because they managed to work together and pull off something really hard. And such a large institution is going to most likely have dissident members who don’t think taking over the world is the right plan for what to do with your powerful tech.
Moreover, there’s going to be plenty of pressures from outside even if you did manage to fill a company full of people who want to take over the world. They’re going to know that that’s kind of not a cool thing to do according to most people. So you’re not going to be taking over the world with AI. You’re going to be taking on specific responsibilities or handing off responsibilities. And so you’ve got an AI system that’s like, “Hey, we can provide this service. We’ll write your spam messages for you. Okay?” So then that responsibility gets handed off. Perhaps OpenAI would choose not to accept that responsibility. But let’s say you want to analyze and summarize a large corpus of texts to summarize what people want. Let’s say you get 10,000 customer service emails in a day and you want something to read that and give you a summary of what really people want.
That’s a tremendously useful thing to be able to do. And let’s say open AI develops the capability to do that. They’ll sell that as a service and other companies will benefit from it greatly. And now, OpenAI has this responsibility that they didn’t have. They’re now responsible for helping Microsoft fulfill customer service requests. And if Microsoft sucks at fulfilling those customer service requests, now open AI is getting complaints from Microsoft because they summarize the requests wrong. So now you’ve got this really complicated relationship where you’ve got a bunch of Microsoft users sending in lots of emails, asking for help that are being summarized by OpenAI, and then hand it off to Microsoft developers to prioritize what they do next with their software. And no one is solely responsible for everything that’s happening because the customer is responsible for what they ask, Microsoft is responsible for what they provide, and open AI is responsible for helping Microsoft understand what to provide based on what the customer’s ask.
Responsibilities get naturally shared out that way unless somebody comes in with a lot of guns and says, “No, give me all the responsibility and all the par.” So militarization of AI is certainly a way that you could see a massive centralization of power from AI. I think States should avoid militarizing AI to avoid scaring other States into militarizing AI. We don’t want to live in a world with militarized AI technologies. So I think if we succeed in heading off that threat and that’s a big if, then we end up in an economy where the responsibilities are being taken on, services are being provided. And then everything’s suddenly very multi-stakeholder, multiple machines servicing multiple people. And I think of delegation as a sort of operation that you perform over and over that ends up distributing those responsibilities and services. And I think about how do you perform a delegation step correctly? If you can do one delegation step correctly, like when Microsoft makes the decision to hand off its customer service interpretation to OpenAI’s language models, Microsoft needs to make that decision correctly.
And it makes that decision correctly. If we define correctly correctly, it’ll be part of an overall economy of delegations that are respectful of humanity. So in my opinion, once you head off militarization, the task of ensuring existential safety for humanity boils down to the task of recursively defining delegation procedures that are guaranteed to preserve human existence and welfare over time.
Lucas Perry: And so you see this area of delegation as being the most x-risky.
Andrew Critch: So it’s interesting. I think delegation prevents centralization of power, which prevents one kind of x-risk. And I think we will seek to delegate. We will seek desperately to delegate responsibilities and distribute power as it accumulates.
Lucas Perry: Why would we naturally do that?
Andrew Critch: People fear power.
Lucas Perry: Do we?
Andrew Critch: If you see something with a lot more power than you, people tend to fear it and sort of oppose it. And separately, people fear having power. If you’re on a team that’s like, “Yeah, we’re going to take over the world,” you’re probably going to be like, “Really? Isn’t it bad? Isn’t that super villain to do that?” So as I predict this, I don’t want to say, “Count on somebody else to adopt this attitude.” I want people listening to adopt that attitude as well. And I both predict and encourage the prevention of extreme concentrations of power from AI development because society becomes less robust then. It becomes this one point of failure where if this thing messes up, everything is destroyed. Whereas right now, it’s not that easy for a centralized force to destroy the world by messing up. It is easy for decentralized forces to destroy the world right now. And that’s how I think it’ll be in the future as well.
Lucas Perry: And then as you’re mentioning and have mentioned, the diffusion of responsibility is where we risk potentially missing core existential safety issues in AI.
Andrew Critch: Yeah, I think that’s the area that’s not only neglected by present day economic incentives, but will likely remain neglected by economic incentives even 10, 20 years from now. And therefore, will be left as the main source of societal scale and existential risk, yeah.
Lucas Perry: And then in terms of the taxonomy you created, can you briefly define the single and multi and the relationships those can have?
Andrew Critch: When I’m talking about AI delegation, I say single-single to mean single human-single AI system, or single human stakeholder and a single AI system. And I always referred to the number of humans first. So if I say single-multi, that means one human stakeholder, which might be a company or a person, and then multiple AI systems. And if I say multi-single, that’s multi human- single AI. And then multi-multi means multi human-multi AI. I started using this in a AGI safety course I was teaching at Berkeley in 2018 because I just noticed a lot of equivocation between students about which kind of scenarios they were thinking about. I think there’s a lot of multi-multi delegation work that is going to matter to industry because when you have a company selling a service to a user to do a job for an employer, things get multi-stakeholder pretty quickly. So I do think some aspects of multi-multi delegation will get addressed in industry, but I think they will be addressed in ways that are not designed to prevent existential risk. They will be addressed in ways that are designed to accrue profits.
Lucas Perry: And so some concepts that you also introduce here are those of control, instruction, and comprehension as being integral to AI delegation. Are those something you want to explore now?
Andrew Critch: Yeah, sure. I mean, those are pretty simple. Like when you delegate something to someone, Alice delegates to Bob, in order to make that decision, she needs to understand Bob, like what’s he capable of? What isn’t he? That’s human AI comprehension. Do we understand AI well enough to know what we should delegate? Then, there’s human AI instruction. Can Alice explain to Bob what she wants Bob to do? And can Bob understand that? Comprehension is really a conveyance of information from Bob to Alice. And then instruction is a conveyance of information from Alice to Bob. A lot of single-single alignment work is focused on how are we going to convey the information? Whereas transparency / interpretability work is more like the Bob to Alice direction. And then control is well, what if this whole idea of communication is wrong and we messed it up and we now just need to stop it, just take back the delegation. Like I was counting on my Gmail to send you emails, but now sending you a bunch of spam. I’m going to shut down my account and i’ll send you messages a different way.
That’s control. And I think of any delegation relationship as involving at least those three concepts. There might be other ones that are really important that I’ve left out. But I see a lot of research as serving one of those three nodes. And so then, you could talk about single-single comprehension. Does this person understand this system? Or we can talk about multi-single. Do this team of people understand this system? Multi-single control would be, can this team of people collectively stop or take back the delegation from the system that they’ve been using or counting on? And then it goes to multi-multi and starts to raise questions like what does it mean for a group of people to understand something? Do they all understand individually? Or do they also have to be able to have a productive meeting about it? Maybe they need to be able to communicate with each other about it too for us to consider it to be a group level understanding. So those questions come up in the definition of multi-multi comprehension, and I think they’re going to be pretty important in the end.
Lucas Perry: All right. So we’ve talked a bunch here already about single-single delegation and much of technical alignment research explores this single human-single AI agent scenario. And that’s done because it’s conceptually simple and is perhaps the most simple place to start. So when we’re thinking about AI existential safety and AI existential risk, how is starting from single-single misleading and potentially not sufficient for deep insight into alignment?
Andrew Critch: Yeah, I guess I’ve said this multiple times in this podcast, how much I think diffusion of responsibility is going to play a role in leaving problems unsolved. And I think diffusion of responsibility only becomes visible in the multi-stakeholder or multi-system or both scenarios. That’s the simple answer.
Lucas Perry: So the single-single gets solved again by the commercial incentives and then the important place to analyze is the multi-multi.
Andrew Critch: Well, I wouldn’t simplify it as much as to say the important places to analyze is the multi-multi because consider the following. If you build a house out of clay instead of out of wood, it’s going to fall apart more easily. And understanding clay could help you make that global decision. Similarly if your goal is to eventually produce societally safe, multi-multi delegation procedures for AI, you might want to start by studying the clay that that procedure is built out of, which is the single-single delegation steps. And single-single delegation steps require a certain degree of alignment between the delegator and the delegate. So it might be very important to start by figuring out the right building material for that, figuring out the right single-single delegation steps. And I know a lot of people are approaching it that way.
They’re working on single-single delegation, but that’s not because they think Netflix is never going to launch the Netflix challenge to figure out how to align recommender systems with users. It’s because the researchers who care about existential safety want to understand what I would call a single-single delegation, but what they would call the method of single-single alignment as a building block for what will be built next. But I sort of think different. I think that’s a great reasonable position to have. I think differently than that because I think the day that we have super powerful single-single alignment solutions is the day that it leaves the laboratory and rolls out into the economy. Like if you have very powerful AI systems that you can’t single-single align, you can’t ship a product because you can’t get it to do what anybody wants.
So I sort of think single-single alignment solutions sort of shorten the timeline. It’s like deja vu. When everyone was working on AI capabilities, the alignment people are saying, “Hey, we’re going to run out of time to figure out alignment. You’re going to have all of these capabilities and we’re not going to know how to align them. So let’s start thinking ahead about alignment.” I’m saying the same thing about alignment now. I’m saying once you get single-single alignment solutions, now your AI tech is leaving the lab and going into the economy because you can sell it. And now, you’ve run out of time to have solved the multipolar scenario problem. So I think there’s a bit of a rush to figure out the multi-stakeholder stuff before the single-single stuff gets all figured out.
Lucas Perry: Okay. So what you’re arguing for then here is your what you call multi-multi preparedness.
Andrew Critch: Yeah.
Lucas Perry: Would you also like to state what the multiplicity thesis is?
Andrew Critch: Yeah. It’s the thing I just want to remind people of all the time, which is don’t forget, as soon as you make tech, you copy it, replicate it, modify it. The idea that we’re going to have a single-single system and not very shortly thereafter have other instances of it or other competitors to it, is sort of a fanciful unrealistic scenario. And I just like reminding people as we’re preparing for the future, let us prepare for the nearly inevitable eventuality that there will be multiple instances of any powerful technology. Some people take that as an argument that, “No, no, no. Actually, we should make the first instance so powerful that it prevents the creation of any other AI technology by any other actor.” And logically, that’s valid. I think politically and socially, I think it’s crazy.
Lucas Perry: Uh-huh (affirmative).
Andrew Critch: I think it’s a good way to alienate anybody that you want to work with on existential risk reduction to say, “Our plan is to take over the world and then save it.” Whereas if your plan is to say, “What principles can all AI technology adhere to, such that it in aggregate will not destroy the world,” you’re not taking over anything. You’re just figuring it out. Like if there’s 10 labs in the world all working on that, I’m not worried about one of them succeeding. But if there’s 10 labs in the world all working on the safe world takeover plan, I’m like, “Hmm, now I’m nervous that one of them will think that they’ve solved safe world takeover or something.” And I kind of want to convert them all to the other thing of safe delegation, safe integration with society.
Lucas Perry: So can you take us through the risk types that you develop in your paper that lead to unsurvivability for humanity from AI systems?
Andrew Critch: Yeah. So there’s a lot of stuff that people worry about. I noticed that some of the things people worry about sort of directly cause extinction if they happen. And then some of them are kind of like one degree of causal separation away from that. So I call it tier one risks in the paper, that refers to things that would just directly lead to the deployment of a unsurvivable or misaligned prepotent AI technology. And then tier two risks are risks that lead to tier one risk. So for example, if AI companies or countries are racing really hard to develop AI faster than each other, so much that they’re not taking into account safety to the other countries around them or the other companies around them, then you get a disproportionate prioritization of progress over safety. And then you get a higher risk of societal scale disasters, including existential risks but not limited to it.
And so you could say fierce competition between AI developers is a tier two risk that leads to the tier one risk of MPAI or UPAI deployment, MPAI being misaligned prepotent AI. And tier one, I have this taxonomy that we use in the paper that I like for sort of dividing up tier one into a few different types that all I think have different technical approaches because my goal is to sort of orient on technical research problems that could actually help reduce existential risk from AI. So got this subdivision. The first one we have is basically diffusion of responsibility, or sometimes we call it unaccountable creators. In the paper, we settled on calling it uncoordinated MPAI deployment.
So the deal is before talking about whether this or that AI system is doing what its creators want or don’t want, can we even identify who the creators are? If the creators were this kind of diffuse economy or oligarchy of companies or countries, it might not be meaningful to say, “Did the AI system do what it’s creators want it?” Because maybe they all wanted a different thing. So a risk type 1A is risks that arise from kind of nobody in particular being responsible for and therefore, no one in particular being attentive to preventing the existential risk.
Lucas Perry: That’s an uncoordinated MPAI event.
Andrew Critch: Yeah, exactly. I personally think most of the most likely risks come from that category, but they’re hard to define and I don’t know how to solve them yet. I don’t know if anybody does. But if you assume we’re not in that case, it’s not uncoordinated. Now, there’s a recognizable identifiable institution Alpha Corp-made AI or America made the AI or something like that. And now you can start asking, “Okay. If there’s this recognizable creator relationship, did the creator know that they were making a prepotent technology?” And that’s how we define type 1B. We’ve got creators, but the creators didn’t know that the tech they were making was going to be prepotent. Maybe they didn’t realize it was going to be replicated or used as much as it was, or it was going to be smarter than they thought for whatever reason. But it just ended up affecting the world a lot more than they thought or being more unstoppable than they thought.
If you make something that’s unstoppably transforming the world, which is what prepotent means, and you didn’t anticipate that, that’s bad. You’re making big waves and you didn’t even think about the direction the waves were going. So I think a lot of risk comes from making tech and not realizing how big its impact is going to be in advance. And so you could have things that become prepotent that we weren’t anticipating and a lot of risks comes from that. That’s a whole risk category. That’s 1B. We need good science and discipline for identifying prepotence or dependence or unstoppability or transformativity all of these concepts. But suppose that’s solved, now we go to type 1C. There are creators contrary to 1A and the creators knew they’re making prepotent tech contrary to 1B. And I think this is weird because a lot of people don’t want to make prepotent tech because it’s super risky, but you could imagine some groups doing it.
If they’re doing that, do they recognize that the thing they’re making is misaligned? Do they think, “Oh yeah, this is going to take over the world and protect everybody. This is the, “I tried to take over the world and I accidentally destroyed it scenario.” So that’s unrecognized misalignment or unrecognized unsurvivability as a category of risk. And for that, you just need a really good theory of alignment with your values if you don’t want to destroy the world. And that’s I think what gets people focused on single-single alignment. They’re like, “The world’s broken. I want to fix it. I want to make magic AI that will like fix the world. It has to do what I want though. So let’s focus on single-single alignment.” But now he’s supposed that problem is solved contrary to type 1A you have discernible creators contrary to 1B, they know they’re playing with fire contrary to 1C, they know it’s misaligned. They know fire burns. That’s kind of plausible. If you imagine people messing with dangerous tech in order to figure out how to protect against it, you could have a lab with people sort of brewing up dangerous cyber attack systems that could break out and exercise a lot of social acumen. If they were really powerful language users, then you could imagine something getting out. So that’s, we call it type 1D, involuntary MPAI deployment, maybe it breaks out or maybe hackers break in and release it. But either way, the creators weren’t trying to do it, then you have type 1E which is contrary to 1D, the creators wanted to release MPAI deployment.
So that’s just people trying to destroy the world. I think that’s less plausible in the short term, more plausible in the longterm.
Lucas Perry: So all of these fall under the category of tier one in your paper. And so all of these directly lead to an existential catastrophe for humanity. You then have tier two, which are basically hazardous conditions, which lead to the realization of these tier one events. So could you take us through these conditions, which may act as a catalyst for eliciting the creation of tier one events in the world?
Andrew Critch: Yeah, so the nice thing about the tier one events is that we use the, an exhaustive decision tree for categorizing it. So any tier one event, any deployment event for a misaligned prepotent AI will fall under one of categories 1A through 1E, unfortunately we don’t have such a taxonomy for tier two.
So tier two is just the list of, hey, here’s four things that seem pretty worrisome. So 2A is, companies or countries racing with each other, trying to make AI real fast and not being safe about it. 2B is economic displacement of humans. So people talk about unemployment risks from AI. Imagine that taken to an extreme where eventually humans just have no economic leverage at all, because all economic value is being produced by AI systems. AI’s have taken all the jobs, including the CEO positions, including the board of directors positions, all using AI’s as their delegates to go to the board meetings that are happening every five seconds because of how fast the AI’s can have board meetings. Now, the humans are just like, “We’re just hoping that all that economy out there is going to not somehow use up all of the oxygen,” to say in the atmosphere, or “Lower the temperature of the earth by 30 degrees,” because of how much faster it would be to run super computers 30 degrees colder.
I think a lot of people who think about x-risk, think of unemployment as this sort of mundane, every generation, there’s some wave of unemployment from some tech. That’s nothing compared to existential risk, but I sort of want to raise a flag here and be, one of the waves of unemployment could be the one that just takes away all human leverage and authority. We should be on the lookout for runaway unemployment that leads to prepotence because loss of control and then human enfeeblement, that’s 2C, the humans are still around, but getting weaker and dumber and less capable of stuff because we’re not practicing doing things because AI is doing everything for us. Then one day we just all trip and fall and hit our heads and die kind of thing. But more realistically, maybe we just fail to be able to make good decisions about what AI technology is doing. And we failed to like notice we should be pressing the stop buttons everywhere.
Lucas Perry: The fruits of the utopia created by transformative AI are too enticing that we become enfeebled and fail at creating existential safety for advanced AI systems.
Andrew Critch: Or we use the systems in a stupid way because we all got worse at arithmetic and we couldn’t imagine the risks and we became scope insensitive to them or something. There’s a lot of different ways you can imagine humans just being weaker because AI is sort of helping us and then type 2D is discourse impairment about existential safety. This is something we saw a lot of in 2014 before FLI hosted the Puerto Rico conference, to just kick off basically discourse on existential safety for AI and other big risks from AGI. Luckily since then, with efforts from FLI and then the Concrete Problems in AI safety paper was a early example of acknowledging negative outcomes.
And then you have the ACM push to acknowledge negative risks and now the NeurIPS broader impact stuff. There’s lots of negative acknowledgement now. The discourse around negative outcomes has improved, but I think discourse on existential safety has a long way to go. It’s progressed, but it’s still has a long way to go. If we keep not being able to talk about it, for example, if we keep having to call existential safety safety, right? If we keep having to call it that, because we’re afraid to admit to ourselves or each other, that we’re thinking of existential stakes, we’re never really going to properly analyze the concept or visualize the outcomes together. I think there’s a big risk from just people sort of feeling like they’re thinking about existential safety, but not really saying it to each other and not really getting into the details of how society works at a large scale and therefore kind of ignoring it and making a bunch of bad decisions.
And I called that discourse impairment and it can happen because it’s taboo or it can happen because it’s just easier to talk about safety because safety is everywhere.
Lucas Perry: All right, so we’ve made it through to what is essentially the first third of your paper here. It lays much of the conceptual and language foundations, which are used for the rest, which try to more explicitly flesh out the research directions for existential safety on AI systems, correct?
Andrew Critch: Yeah. And I would say the later sections are a survey of research directions attacking different aspects and possibly exacerbating different aspects too. You earlier called this a research agenda. But I don’t think it’s quite right to call it an agenda because first of all, I’m not personally planning to research every topic in here, although I would be happy to research any of them. So this is not like, “Here’s the plan we’re going to do all these areas.” It’s more like, “Here’s a survey of areas and an analysis of how they flow into each other.” For example, single-single transparency research, that can flow in to coordination models for single-multi comprehension. It’s a view rather than a plan, because I think a plan should take into account more things like what’s neglected, what’s industry going to solve on its own?
My plan would be to pick sections out of this report and call those my agenda. My personal plan is to focus more on multi-agent stuff. Some also social metacognition stuff that I’m interested in. So if I wrote a research agenda, it would be about certain areas of this report, but the rest of the report is really just trying to look at all of these areas that I think relate to existential safety and it kind of analyzing how they relate.
Lucas Perry: All right, Andrew, well, I must say that on page 33, it says, “This report may be viewed as a very coarse description of a very long term research agenda, aiming to understand and improve blah, blah, blah.”
Andrew Critch: It’s true. It may be viewed as such and you may have just viewed it as such.
Lucas Perry: Yeah, I think that’s where I got that language from.
Andrew Critch: It’s true. Yeah, and I think if an institution just picked up this report and said, “This is our agenda.” I’d be like, “Cool, go for it. That’s a great plan.”
Lucas Perry: All right. I’m just getting you back for nailing me on the definition of AI alignment.
Andrew Critch: Okay.
Lucas Perry: Let’s hit up on some of the most important or key aspects here then for this final part of the paper. We have three questions here. The first is, “How would you explain the core of your concerns about, and the importance of flow through effects?” What are flow-through effects and why are they important for considering AI existential safety?
Andrew Critch: Flow through effects just means if A affects B and B affects C, then indirectly A affects C. Effects like that can be pretty simple in physics, but they can be pretty complicated in medicine and they might be even more complicated in research. If you do research on single-single transparency, that’s going to flow through to single-multi instruction. How is a person going to instruct a hierarchy of machines? Can they delegate to the machines to delegate to other machines? Okay, now can I understand? Okay, cool. There’s a flow through effect there. Then that’s going to flow through to multi-multi control. How can you have a bunch of people instructing a bunch of machines and still have control over them? If the instructions aren’t being executed to satisfaction, or if they’re going to cause a big risk or something.
And some of those flow through effects can be good, some of them could be bad. For example, you can imagine work in transparency flowing through to really rapid development in single-multi instruction, because you can understand more of what all the little systems are doing. You can tell more of them what to do and get more stuff done. Then that could flow through to disasters in multi-multi control because you’ve got races between powerful institutions that are delegating to large numbers of individual systems that they understand separately. But the interaction of which at a global scale are not understood by any one institution. So then you just get this big cluster of pollution or other problems being caused for humans, as a side effect. Just thinking about a problem, that’s a sub problem of the final solution is not always helpful, societally. Even if it is helpful to you personally, understanding how to approach the helpful societal scale solution. My personal biggest area of interest, I’m kind of split between two things.
One is, if you have a very powerful system and several stakeholders with very different priorities or beliefs, trying to decide a policy for that system. Imagine U.S., China and Russia trying to reach an agreement on some global cyber security protocol, that’s AI mediated or Uber and Waymo, trying to agree on what are the principles that their cars are going to follow when they’re doing lane changes. Are they going to try to intimidate each other to get a better chance at that lane changes? Is that going to put the humans at risk? Yes, okay. Can we all not intimidate each other and therefore not put the passengers at risk? That’s a big question for me, is how can you make systems that have powerful stakeholders in the process of negotiating for control over the system?
It’s like the system is not even deployed yet. We’re considering deploying it and we’re negotiating for the parameters of the system. I want the system to have a nice API, for the negotiating powers, to sort of turn knobs until they’re all satisfied with it. I call that negotiable AI. I’ve got a paper called Negotiable Reinforcement Learning with a student. I think that kind of encapsules the problem, but it’s not a solution to the problem by any means. It’s just merely drawing attention to it. That’s like a one core thing that I think is going to be really important as multi-stakeholder control. Not multi-stakeholder alignment, not making all the stakeholders happy, but making them work together in sharing the system, which might sometimes leave one of them unhappy. But at least they’re not all fighting and causing disasters from the externalities of their competition. The other one is almost the same principle, but where the negotiation is happening between the AI systems instead of the people.
So how do you get two AI systems, like System A and System B serving Alice and Bob, Alice and Bob want very different things. Now A and B have to get along. How can A and B get along, broker an agreement about what to do that’s better than fighting. Both of these areas of research are kind of trying to make peace between the human institutions controlling a powerful system. And the second case is peace between two AI systems. I don’t know how to do this at all. That’s why I try to focus on it. It’s sort of nobody’s job, except for maybe the UN and the UN doesn’t have… The cars getting along thing is kind of like a National Institute of Standards thing maybe, or a partnership, an AI thing maybe so maybe they’ll address that, but it’s still super interesting to me and possibly generalizable to big, higher stakes issues.
So I don’t claim that it’s going to be completely neglected as an area. It’s just very interesting at a technical level it seems neglected. I think there’s lots of policy thinking about these issues, but what shape does the technology itself need to have to make it easy for policymakers to set the standards, for it to be sort of negotiable and cooperative? That’s where my interests lie.
Lucas Perry: All right. And so that’s also matches up with everything else you said, because those are two sub-problems of multi-multi situations.
Andrew Critch: Yes.
Lucas Perry: All right. So next question is, is there anything else you’d like to add then to how it is the thinking about AI research directions affect AI existential risk?
Andrew Critch: I guess I would just add, people need to feel permission to work on things because they need to understand them, rather than because they know that it’s going to help the world. I think there’s a lot of paranoia about like, if you manage to care, but existential risks you’re like thinking about these high stakes and it’s easy to become paranoid. What if I accidentally destroy the world by doing the wrong research or something? I don’t think that’s a healthy state for a researcher, maybe for some it’s healthy, but I think for a lot of people that I’ve met, that’s not conducive to their productivity.
Lucas Perry: Is that something that you encounter a lot, people who have crippling anxiety over whether the research direction is correct?
Andrew Critch: Yeah, and varying degrees of crippling, some that you would actually call anxiety, the person’s experiencing actual anxiety. But more often it’s just a kind of festering unproductivity. It’s thinking of an area, “But that’s just going to advanced capabilities, so I won’t work on it,” or like think of an area it’s like, “Oh, that’s just going to hasten the economic deployment of AI systems, so I’m not going to work on it.” I do that kind of triage, but more so because I want to find neglected areas, rather than because I’m afraid of building the wrong tech or something. I find that mentality doesn’t inhibit my creativity or something. I want people to be aware of flow through effects and that any tech can flow through to have a negative impact that they didn’t expect. And because of that, I want everyone to sort of raise their overall vigilance towards AI technology as a whole. But I don’t want people to feel paralyzed like, “Oh no, what if I invent really good calibration for neural nets? Or what if I invent really good, bounded rationality techniques and then accidentally destroyed the world because people use them.”
I think what we need is for people to sort of go ahead and do their research, but just be aware that X-risk is on the horizon and starting to build institutional structures to make higher and higher stakes decisions about AI deployments, along with being supportive of areas of research that are conducive to those decisions being made. I want to encourage people to go into these neglected areas that I’m saying, but I don’t want people to think I’m saying they’re bad for doing anything else.
Lucas Perry: All right. Well, that’s some good advice then for researchers. Let’s wrap up here then on important questions in relevant multi-stakeholder objectives. We have four here that we can explore. The first is facilitating collaborative governance and the next is avoiding races by sharing control. Then we have reducing idiosyncratic risk taking, and our final one is existential safety systems. Could you take us through each of these and how they are relevant multi-stakeholder objectives?
Andrew Critch: Yeah, sure. So the point of this section of the report, it’s a pause between the sections about research for single human stakeholders and research for multiple human stakeholders. It’s there sort of explain why I think it’s important to think of multiple human stakeholders and important, not just in general. I mean, it’s obviously important for a lot of aspects of society, but I’m trying to focus on why it’s important to existential risk specifically.
So the first reason, facilitating collaborative governance is that I think it’s good if people from different backgrounds with different beliefs and different priorities can work together in governing AI. If you need to decide on a national standard, if you need an international standard, if you need to decide on rules that AI is not allowed to break, or that developers are not allowed to break. It’s going to suck if researchers in China make up some rules and researchers in America makeup different rules and the American rules don’t protect from the stuff that the Chinese rules protect from and the Chinese rules don’t protect from the stuff the American rules protect from. Moreover, that systems interacting with each other are going to not protect from either of those risks.
It’s good to be able to collaborate in governing things. Thinking about systems and technologies having a lot of stakeholders is key to preparing those technologies in a form that allows them to be collaborated over. Think about Google docs. I can see your cursor moving when you write in a Google doc. That’s really informative in a way that other collaborative document editing software does not allow. I don’t know if you’ve ever noticed how very informative it is to see where someone’s cursor is versus using another platform where you can only see the line someone’s on, but you can’t see what character they’re typing right now, that you can’t see what word they’re thinking. You’re like way, way, way less in tune with each other when you’re writing together, when you can’t see the cursors.
That’s an example of a way in which Google docs just had this extra feature that makes it way easier to negotiate for control, because if you’re not getting into an edit war, if I’m editing something, I’m not going to put my cursor where your cursor is. Or if I start backspacing a word that you just wrote, you know I must mean that, it must be important change. I just interrupted your cursor. Maybe you’re going to let me finish that backspace and see what the hell I’m doing. There’s this negotiability over the content of the document. It’s a consequence of the design of the interface. I think similarly AI technology could be designed with properties that make it easier for different stakeholders to cooperate in exercising, in the act of exercise and control over the system and its priorities. I think that sort of design question is key to facilitating collaborative governance because you can have stakeholders from different institutions, different cultures collaborating in the act of governing or controlling systems and observing what principles the systems need to have, need to adhere to for the purposes of different cultures or different values and so on.
Now, why is that important? Well, it’s lots of warm fuzzies from people working together and stuff. But one reason it’s important is that it reduces incentives to race. If we can all work together to set the speed limit, we don’t all have to drive as fast as we can to beat each other. That’s the section 7.2 is avoiding races by share and control and then section 7.3 is reducing idiosyncratic risk taking. Basically everybody kind of wants different things, but there’s a whole bunch of stuff we all don’t want. This kind of comes back to what you said about there being basic human values. Most of us don’t want humanity to go extinct. Most of us don’t want everyone to suffer greatly, but everybody kind of has a different view of what utopia should look like. That’s kind of maybe where the paretotopia concept came from.
It’s like everybody has a different utopia in mind, but nobody wants dystopia. If you imagine a powerful AI technology that might get deployed, and there’s a bunch of people on the committee deciding to make the deployment decision or deciding what features it should have, you can imagine one person on the committee being like, “Well, this poses a certain level of societal scale risk, but it’s worth it because of the anti-aging benefits that the AI is going to produce through the research, that’s going to be great.” Then another person on the committee being like, “Well, I don’t really care about anti-aging, but I do care about space travel. I want it to take a risk for that.” Then they’re like, “Wait a minute, I think we have this science assistant AI. We should use it on anti-aging not space.” And the space travel person’s like, “We should use it on space travel, not anti aging.”
Because of that, they don’t agree, that slows progress, but maybe a little slower progress is maybe a safer thing for humanity. Everyone has their agenda that they want to risk the world for, but because everyone disagrees and what risks are worth it, you sort of slow down and say, “Maybe collectively, we’re just not going to take any of these risks right now and we’ll just wait until we can do it with less risk.” So reducing idiosyncratic risk taking is just my phrase for the way everyone’s individual desire to take risks kind of averages out. Whereas every member of the committee doesn’t want human extinction so that doesn’t get washed out. It’s like everybody wants it to not destroy the world. Whereas not everybody wants it to colonize space or not everybody wants it to cure aging. You end up conservative on the risk, if you can collaboratively govern.
Then you’ve got existential safety systems, which is the last thing. If we did someday try to build AI tech that actually protects the world in some way, like say through cybersecurity or through environmental protection, that’s terrifying by the way, AI that controls the environment. But anyway, it’s also really promising, maybe we can clean up. It’s just the big move, setting control of the environment to AI systems is a big move. But as long you got lots of off switches, it’s maybe it’s great. Those big moves are scary because of how big they are. A lot of institutions would just never allow it to happen because of how scary it is. It’s like, “All right, I’ve got this garbage cleanup, AI is just going to actually go clean up all the garbage, or it’s going to scrub all the CO2 with this little replicating photosynthetic lab here. That’s going to absorb all the carbon dioxide and store it as biofuel. Great.” That’s scary. You’re like, whoa, you’re just unrolling the self replicating biofuel lab all over the world. People won’t let that happen.
I’m not sure what the right level of risk tolerance is for saving the world versus risking the world. But whatever it is, you are going to want existential safety safety nets, literal existential safety nets there to protect from big disasters. Whether the system is just an algorithm that runs on the robots that are doing whatever crazy world intervention you’re doing, or if it’s actually a separate system. But if you’re making a big change to the world for the sake of existential safety, you’re not going to get away with it unless a lot of people are involved in that decision. This is kind of a bid to the people who really do want to make big world interventions. Sometimes for the sake of safety, you’re going to have to appeal to a lot of stakeholders to sort of be allowed to do that.
So those are four reasons why I think developing your tech in a way that really is compatible with multiple stakeholders is going to be societally important and not automatically solved by industry standards. Maybe solved in special cases that are profitable, but not necessarily generalizable to these issues.
Lucas Perry: Yeah, the set of problems that are not naturally solved by industry and incentives, but that are crucial for existential safety are the set of problems it seems that we crucially need to identify and anticipate and engage in research today. Being mindful of flow through effects, such that we’re able to have as much leverage on that set of problems, given that they’re most likely not to be solved without a lot of foresight and intervention from the outside of industry and the normal flow of incentives.
Andrew Critch: Yep, exactly.
Lucas Perry: All right, Andrew wrapping things up. I just want to offer you a final bit of space for you to give any final words you’d like to say about the paper or AI existential risk. If there’s anything you feel is unresolved or you’d really like to communicate to everyone.
Andrew Critch: Yeah, thanks. I’d say if you’re interested in existential safety or something adjacent to it, use specific words for what you mean instead of just calling it AI safety all the time. Whatever your thing is, maybe it’s not existential safety, maybe it’s a societal scale risk or single-multi alignment or something, but try to get more specific about what we’re interested in. So that it’s easier for newcomers thinking about these topics, to know what we mean when we say them.
Lucas Perry: All right. If people want to follow you or get in touch or find your papers and work, where are the best places to do that?
Andrew Critch: For me personally, or David Krueger, the other coauthor on this report, and you could just Google our names and then we’ll have our research homepage show up and then you can see what our papers are or obviously Google Scholar is always a good avenue. Google Scholar sorted by year is a good trick because you can see what people are working on now, but there’s also the Center for Human Compatible AI where I work. There’s a bunch of other research going on there that I’m not doing, but I’m also still very interested in, and I’d probably be interested in doing more work research in that vein. I would say check out humancompatible.ai or acritch.com, for me personally. I don’t know what David’s homepage is, but I’m sure you can find them by Googling David Krueger.
Lucas Perry: All right, Andrew, thanks so much for coming on and for your paper, I feel like I honestly gained a lot of perspective here on the need for clarity on definitions and what we mean. You’ve given me a better perspective on the kind of problem that we have and the kind of solutions that it might require and so for that, I’m grateful.
Andrew Critch: Thanks.
















 The workshop was structured according to a taxonomy that incorporates both near and long term safety research into three areas — specification, robustness, and assurance.
The workshop was structured according to a taxonomy that incorporates both near and long term safety research into three areas — specification, robustness, and assurance.